Database Interview Questions — schema-first grading criteria
A practical database interview prep guide for software engineers: the question families that repeat, how to explain schema and indexing tradeoffs, and the drill plan that keeps database rounds concrete.
Database interview questions are not memory quizzes on normal forms or isolation anomalies. They test whether you can model the data, predict the access pattern, and explain why the design stays correct under real traffic.
A database is a system that stores and organizes data so you can query it fast. Interview rounds test whether you can model the data, pick the right indexes, and predict what breaks under load. Joins are the easy part.
Database interviews sit in the awkward space between SQL and full system-design territory. Across the database rounds the research has traced, the failure pattern is always the same split. Some candidates answer them like pure SQL rounds and start writing joins before they have named the entities. Others answer them like huge architecture prompts and start talking about Kafka, caching, and sharding before they have decided how one row relates to another. DesignGurus' database interview guide frames the four pillars that actually get tested: ACID properties, normalization, indexing, and SQL proficiency.
The better move is smaller and more concrete:
- define the data model
- define the important queries
- define the constraints and failure modes
- then talk about scaling or storage tradeoffs
LeetCode's SQL 50 frames SQL as a dedicated one-month interview plan, and
open-source prep repos treat Databases as a first-class interview track. The
signal is clear: candidates are now expected to handle both query-writing and
higher-level database reasoning.
What interviewers are actually testing
A strong database answer proves five things:
- You can identify the right entities and the right grain.
- You can choose relationships and constraints that preserve correctness.
- You can connect expected queries to the indexes that support them.
- You understand which operations need transactional protection.
- You can explain tradeoffs without hiding behind vendor buzzwords.
Interviewers mainly want to trust that your schema stays correct under real usage.
The five database question families that keep repeating
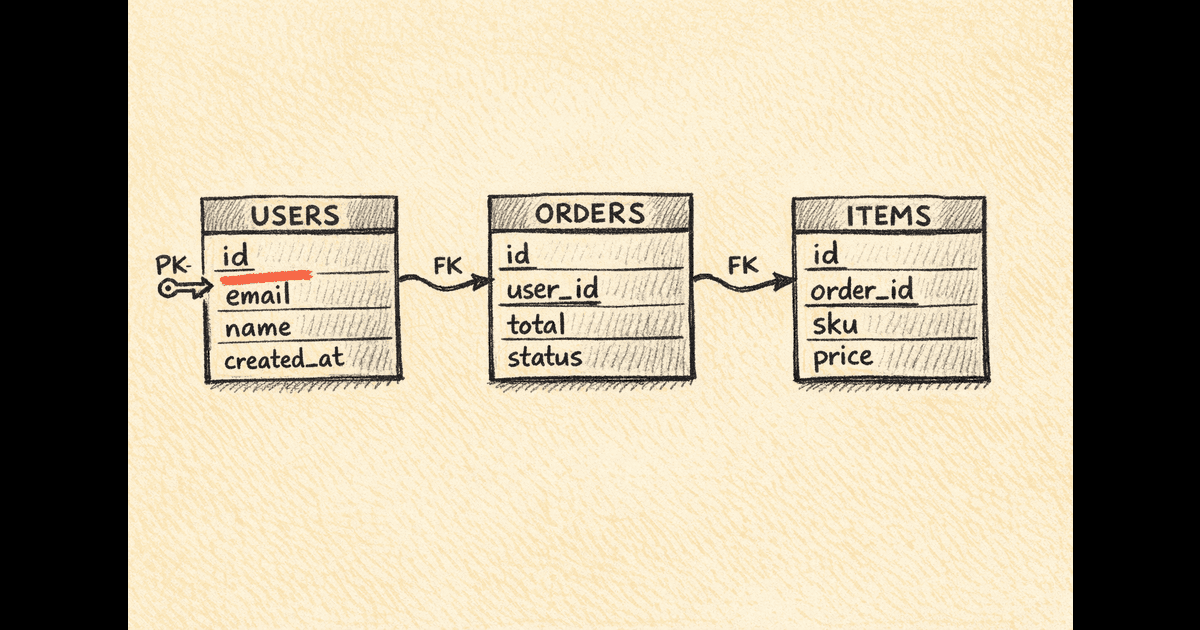
1. Schema design and relationships
This is the classic prompt family:
- design orders and order items
- design users, teams, and memberships
- design posts, comments, and reactions
- design subscriptions, invoices, and payments
The core skill is naming the entities, choosing primary keys, and separating one-to-many relationships cleanly.
CREATE TABLE orders (
id BIGSERIAL PRIMARY KEY,
user_id BIGINT NOT NULL,
status TEXT NOT NULL,
created_at TIMESTAMPTZ NOT NULL DEFAULT NOW()
);
CREATE TABLE order_items (
id BIGSERIAL PRIMARY KEY,
order_id BIGINT NOT NULL REFERENCES orders(id),
product_id BIGINT NOT NULL,
quantity INTEGER NOT NULL,
unit_price_cents INTEGER NOT NULL
);
CREATE INDEX idx_orders_user_created_at
ON orders (user_id, created_at DESC);The useful talk-track is:
- "
ordersis the parent entity." - "
order_itemsis separate because an order has many line items." - "I expect a common read path of 'show this user's recent orders,' so I index
user_idplus descendingcreated_at."
That is a stronger answer than saying "I would normalize the schema."
Normalization is a tool, not the answer. Microsoft Learn's normalization guide defines it well: "organizing data to eliminate redundancy and inconsistent dependency." In interviews, start with a clean relational model and only denormalize if you can name the read pressure that forces it. I tell every candidate: if you cannot name the specific query that would be too slow without denormalization, you are optimizing on imagination.
2. Indexing questions
Many database interviews are really indexing interviews wearing a schema mask.
Typical versions:
- how would you speed up lookup by email
- how would you fetch a user's recent events
- why is this query still slow after we added one index
- what index would help this join
The PostgreSQL index documentation makes the tradeoff explicit: "B-tree indexes fit the most common situations — they handle equality and range queries on data that can be sorted." But every extra index also adds maintenance cost on writes. That is exactly what interviewers want to hear, and I have seen candidates lose points by adding five indexes without naming the query any of them serves.
A good indexing answer should name:
- the query pattern
- the column or column order
- the write cost you are accepting
Example:
- "If the common query is
WHERE user_id = ? ORDER BY created_at DESC, I would use a composite index on(user_id, created_at DESC)." - "If writes are extremely hot, I would avoid adding speculative indexes until I know the read path is important enough."
Weak answer:
- "I would just add an index."
That is too vague to be useful.
3. Transactions and concurrency
This is the part candidates skip and then regret.
Prompts often look like:
- prevent double-booking the same seat
- avoid overselling inventory
- ensure one coupon redemption per user
- keep a money transfer consistent across two rows
The right move is not to start by naming isolation levels from memory. Start by stating the invariant.
Examples:
- "A seat can only be sold once."
- "Inventory cannot go below zero."
- "A user can only redeem this promotion one time."
Then explain the protection:
- transaction
- row-level lock or equivalent coordination
- unique constraint where applicable
- retry behavior if contention occurs
Isolation only matters in context. If the interviewer pushes, talk about the specific anomaly you are avoiding. Decide whether READ COMMITTED is enough or whether the workflow needs stricter guarantees. The PostgreSQL transaction isolation docs put it precisely: "Serializable guarantees any concurrent execution of a set of Serializable transactions produces the same effect as running them one at a time in some order." You do not need to recite that. You do need to know Serializable is the strongest guarantee and most apps run weaker for performance.
4. SQL vs NoSQL tradeoffs
This question shows up constantly and gets answered badly.
Do not treat it like a religion quiz. HelloInterview's SQL vs NoSQL guide frames it exactly right: "don't immediately jump to NoSQL just because the problem mentions 'scale' — probe for actual requirements." MongoDB's own comparison is surprisingly balanced: relational suits structured schemas with medium-to-large datasets, non-relational excels at horizontal scalability and unstructured data.
A strong answer sounds more like:
- "I would start relational if the data has clear relationships, transactional invariants, and query flexibility matters."
- "I would consider a document or key-value model if access patterns are narrow, the data is mostly hierarchical, and cross-entity transactions are not the core difficulty."
That is already enough for most interviews.
The failure mode is saying "NoSQL scales better," as if that settles anything.
Scales for what?
- reads
- writes
- global distribution
- schema flexibility
- operational simplicity
Unless you name the pressure, the tradeoff is still hand-waving.
5. Read paths, write paths, and growth
This is where database questions start blending into broader system design:
- when would you add a replica
- when would you partition by time
- when would you archive cold data
- when does help more than a new index
The best answer is usually staged:
- fix the schema
- fix the query
- add the right index
- measure
- only then talk about replicas, partitioning, or cache layers
That sequence makes you sound practical instead of theatrical.
Common mistakes that cost easy points
Designing tables before naming queries
If you cannot say what the application needs to read or write, you are designing blind.
Using "add an index" as a magic phrase
An index only makes sense relative to a concrete lookup, filter, sort, or join.
Treating transactions like backend decoration
If the prompt contains money, inventory, booking, uniqueness, or retries, the database correctness story is part of the solution.
Overusing NoSQL as an escape hatch
Interviewers usually want to know whether you understand the relational model first. Jumping to NoSQL too early can sound like you are dodging the hard part.
Speaking at the wrong altitude
Too low:
- naming every column type for ten minutes
Too high:
- saying "use microservices and shard by user" before one query is clear
The sweet spot is entity -> query -> constraint -> index -> scale.
How to practice database interviews fast
If you only have one serious prep block, do this:
- Pick three product shapes: marketplace, messaging, subscriptions.
- For each one, write the core entities and one-to-many relationships.
- Name the three most important reads and writes.
- Add the one index you are most confident about for each read path.
- Pick one concurrency failure: double booking, duplicate redemption, or stale inventory.
- Explain the invariant and the transaction story out loud.
That will do more for your interview performance than reading a giant glossary of database terminology.
If your SQL execution is also weak, pair this guide with SQL Interview Questions. If your answers keep ballooning into distributed-systems diagrams, tighten the framing with API Design Interview Questions.
The real goal
Database interview questions are not trying to turn you into a query planner or storage-engine expert.
They are trying to find out whether you can build a data model that survives real usage:
- the rows stay consistent
- the important reads stay fast
- the write path preserves invariants
- the tradeoffs are intentional
If you can explain those four things calmly, most database rounds stop feeling mysterious.
Fin and Coco are StrongYes editorial personas from the Council of Ternary Vertices — a trinary-star animal civilization that studies Earth's coding-interview process. Anecdotes map animal-universe experience to human interview mechanics; they are NEVER human-career claims. External citations link to public primary sources.
Grounded in LeetCode's SQL 50 study plan, DesignGurus' database interview guide, Microsoft Learn normalization docs, PostgreSQL index + transaction-isolation docs, HelloInterview SQL-vs-NoSQL guide, and MongoDB's relational-vs-non-relational comparison.
Last verified Apr 19, 2026.
Practice Database.
Reading builds recognition. Explaining builds recall. Run these problems with Fin or Coco.